本系列文章参考国外编程高手鲁斯兰的博客文章《Let’s Build A Simple Interpreter》。
这篇文章会为大家介绍一种重要的数据结构,这种数据结构会在本系列文章剩余的部分中使用。
在之前的文章中,我们所实现的语法分析器和解释器是混合在一起的,解释器将语法分析器识别出的某种结构(加法、减法、乘法和除法)进行求值。
这种解释器叫做语法导向(syntax-directed)解释器,它们通常只对输入进行一次传递,适用于基本语言应用程序。
如果想让解释器解释更复杂的编程语言结构,我们需要建立IR(Intermediate Representation:中间表示)。
实际上,我一直隐瞒了一件事情。
在鲁斯兰的博客中,最终的目标并不是一个计算功能的解释器,而是一个编程语言(Pascal)子集的解释器。
鲁斯兰的第一篇文章中,出现了一段Pascal语言代码,最终目的就是做出一个简单的可以解释Pascal编程语言子集的解释器。
这不是我不厚道,大家也看到了,前六篇文章,你一点Pascal语言的影子都没看到,所以我们为什么一开始就给自己增加难度呢?
而且,我告诉你,这篇文章依然看不到Pascal语言的影子。
不过,从这篇文章开始,我们的解释器开始真正的朝着能够解释编程语言的方向迈进。
上面所说的IR(中间表示),就是关键的一步。
我们的语法分析器将负责建立一个IR,而我们的解释器将用来解释表示为IR的输入。
一、树(Tree)
我们看看文章开始所说的数据结构:树(Tree)。
事实证明,树(Tree)是一个非常适合IR的数据结构。

先来看一些关于树的术语:
- 树是由一个或多个节点组成的带有层次结构的数据结构。
- 树有一个根节点(Root),它是顶部节点。
- 根节点以外的所有节点都有唯一的父节点(Parent)。
- 没有子节点的节点称为叶节点(Leaf)。
- 除根节点外,具有一个或多个子节点(Children)的节点称为内部节点(Interior )。
- 子节点也可以是完整的子树(Subtrees)。
在计算机科学中,我们从顶部的根节点开始向下倒置树,树枝向下生长。
例如,表达式“2*7+3”的树结构如下:
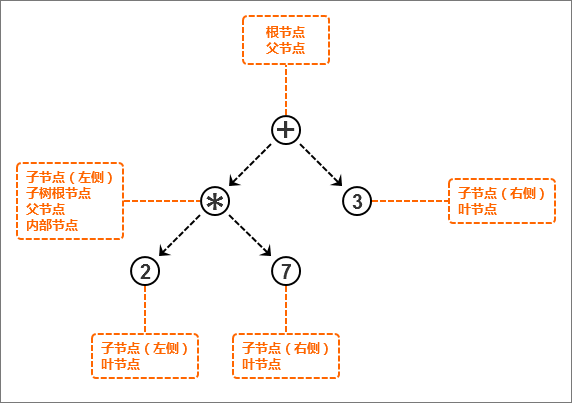
上图中标记为“*”的节点相对于标记为“2”和“7”的节点是父节点,“2”和“7”是它的子节点,从左到右排序。
而相对于标记为“+”的节点,标记为“*”的节点是它的子节点。
并且,树的根节点(标记为“+”的节点)左侧子节点是一个完整的子树,具有自己的子节点;这个子树的根节点是标记为“*”的节点。
还有,在整个树结构中,标记为“*”的节点既有父节点(+),又有子节点(2和7),所以它是内部节点。
最后,标记为“3”、“2”和“7”的节点都是子节点,但是它们没有子节点,所以它们也是叶节点。
二、解析树(Parse Tree)
树和我们将要创建的IR有什么关系呢?
我们将在这个系列文章中使用的IR称为AST(Abstract-Syntax Tree:抽象语法树)。
但是在深入研究AST之前,我们需要先简单地了解一下解析树(Parse Tree)。
我们不需要手动创建解析树,也不需要在我们的解释器中使用解析树,但它可以通过可视化的跟踪语法分析器的执行,帮助我们理解语法分析析器是如何解释输入的。
而且还会将它与AST进行比较,来了解为什么AST比解析树更适合于中间表示。
那么,什么是解析树呢?
解析树(也叫做具体语法树)是根据语法定义来表示语言结构中句法结构的树。
它基本上显示了语法分析器是如何识别语言构造的,换句话说,它显示了语法的起始符号是如何在编程语言中派生出某个字符串的。
当语法分析器试图识别某个语言构造时,会调用堆栈隐式地表示解析树,并由语法分析器自动构建在内存中。(这一句看不懂也没关系,继续向下阅读。)
举个例子,表达式2 * 7 + 3的解析树:
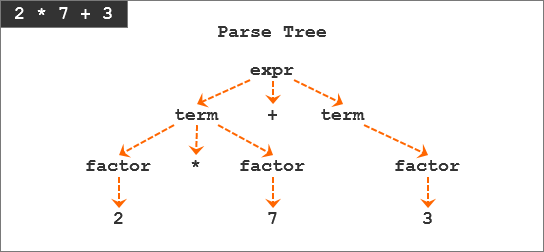
有没有感觉很熟悉?之前的文章中,为了讲清语法分析器的工作流程,曾经画过下面这张图。

所以,解析树理解起来并没有想象中困难。
再次强调,不要被术语吓倒,就像我们刚刚接触编程时看到“变量”、“函数”以及“对象”这些术语一样,理解了,就会变得简单。
回到解析树的内容上来。
在上面的解析树图片中,我们能够看到以下几点:
- 解析树记录了一系列语法分析器识别输入的规则。
- 解析树的根节点是文法开始符号标记。
- 每个内部节点代表一个非终结符,即一个文法规则应用程序,例如:expr、term和factor。
- 每个叶节点表示一个记号(Token)。
提示:看到了吧?以往文章学过的内容都有很强的关联性。
鲁斯兰为我们提供了一个叫做“genptdot.py”的小工具,可以生成不同算术表达式的解析树图片。(这个工具不支持Windows系统)
使用这个工具,首先需要安装“Graphviz”包,在命令行终端运行以下命令后,可以打开生成的图像文件“parsetree.png”,查看命令行参数中算术表达式的解析树:
python genptdot.py "14 + 2 * 3 - 6 / 2" > parsetree.dot && dot -Tpng -o parsetree.png parsetree.dot
下面就是是表达式“14 + 2 * 3 - 6 / 2”生成的解析树图像:
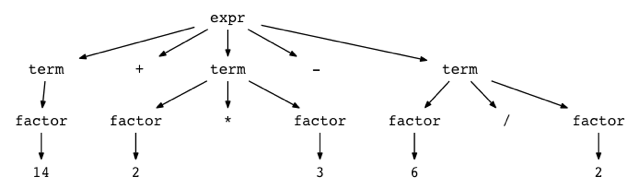
如果使用的是Linux系统,可以尝试输入不同的算术表达式查看解析树。
三、抽象语法树(Abstract-Syntax Tree)
抽象语法树(AST)是中间表示(IR),我们将在这个系列文章的其余部分中大量使用。
它是我们的解释器的核心数据结构之一。
我们先来对比一下算术表达式“2 * 7 + 3”的AST和解析树:
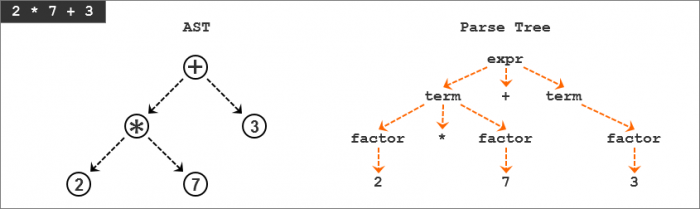
正如从上面的图片中看到的,AST捕获输入的本质,并且更小。
下面是AST和解析树之间的主要区别:
- AST使用运算符或操作符作为根节点和内部节点,并使用操作数作为它们的子节点。
- 与解析树不同,AST不使用内部节点来表示语法规则。
- AST不代表真实语法中的每一个细节(这就是为什么它们被称为抽象),例如没有规则节点,也没有括号。
- 与同一语言构造的解析树相比,AST更加简练。
那么,什么是抽象语法树?
抽象语法树(AST)是表示语言构造的抽象句法结构的树,其中每个内部节点和根节点表示操作符,节点的子节点表示该操作符的操作数。
AST比解析树更紧凑。
我们再来看一下算术表达式“7 +((2 + 3))”的AST和解析树:
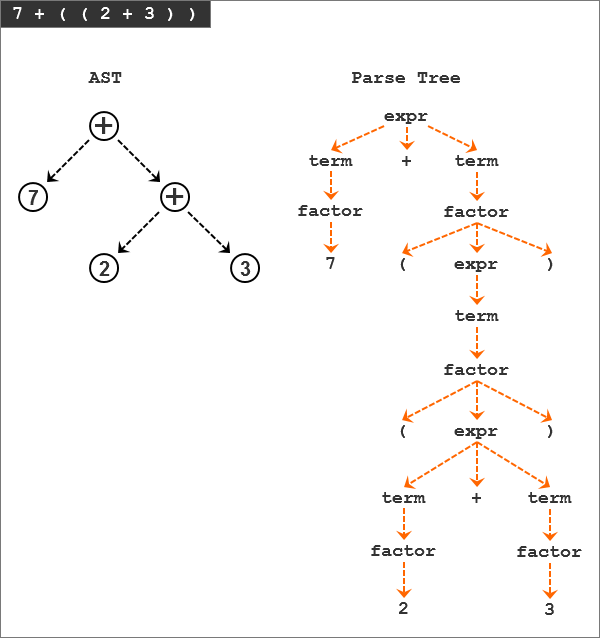
通过对比,我们可以看到AST比解析树小很多,但仍然捕获输入的本质。
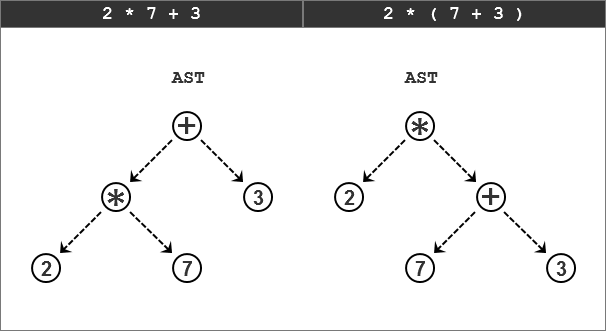
但是,如何在AST中表示运算符优先级呢?
我们需要把优先级高的运算符放在更低的位置。
例如,算术表达式“2 * 7 + 3”和“2 * ( 7 + 3 )”。
再来看算术表达式“1 + 2 + 3 + 4 + 5 ”的AST。
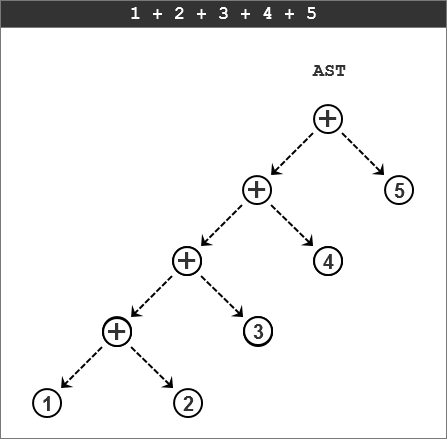
从上面的两个例子中可以看出,具有较高优先级的运算符会处在树中较低的位置。
四、结合AST修改语法生成器
我们编写一些代码,实现不同的AST节点类型,并修改我们的语法生成器来生成由这些节点组成的AST。
1、节点基类(AST)
所有的节点类都继承自这个类。
当前,这个类还没有任何内容。
示例代码:
class AST: # 定义抽象语法树类作为基类
pass # 暂时无内容
2、运算符类(BinaryOperator)
在AST模型中有四个运算符和整数操作数。
运算符包括是加法、减法、乘法和除法。
我们可以为运算符都创建一个单独的类来表示每个操作符,例如:“AddNode”、“SubNode”、“MulNode”和“DivNode”。
不过,在这里我们只创建一个“BinOperator”类,用来表示所有四个二元运算符(二元运算符是在两个操作数上操作的运算符)。
示例代码:
class BinOperator(AST): # 定义运算符节点类
def __init__(self, left, operator, right): # 初始化
self.left = left # 运算符左侧子节点
self.token = self.operator = operator # 运算符记号和运算符节点
self.right = right # 运算符右侧子节点
3、数字类(Num)
示例代码:
class Num(AST): # 定义数字节点类
def __init__(self, token): # 初始化
self.token = token # 数字记号
self.value = token.value # 数字的值
注意:所有节点都存储了用于创建节点的记号。
4、语法分析器类(Parser)
这一次,我们将语法分析器也独立出来。
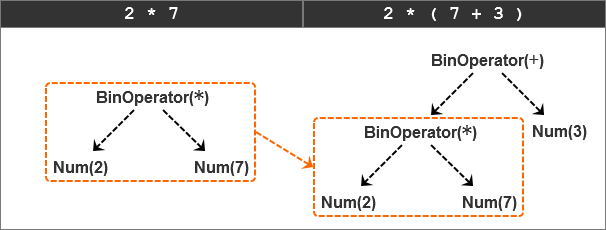
通过前面的学习,我们知道算术表达式“2 * 7 + 3”的解析过程是先得到“2 * 7”,然后再得到“2 * 7 + 3”。
在Python的Shell中,我们可以通过代码模拟这个过程。
>>> from spi import Token, MUL, PLUS, INTEGER, Num, BinOperator >>> >>> mul_token = Token(MUL, '*') >>> plus_token = Token(PLUS, '+') >>> mul_node = BinOp( ... left=Num(Token(INTEGER, 2)), ... op=mul_token, ... right=Num(Token(INTEGER, 7)) ... ) >>> add_node = BinOperator ( ... left=mul_node, ... op=plus_token, ... right=Num(Token(INTEGER, 3)) ... )
用AST定义新的节点类也是这样的过程,如下图:
根据上面的过程,我们修改的解析器代码,让它能够创建并返回一个通过AST进行输入(算术表达式)识别的结果,也就是一个树。
示例代码:
class Parser: # 定义语法分析器的类
def __init__(self, lexer):
self.lexer = lexer # 接收词法分析器对象
self.current_token = lexer.get_next_token()
def error(self): # 增加语法分析器的错误方法
raise Exception('警告:错误的输入内容!')
def eat(self, value_type):
if self.current_token.value_type == value_type:
self.current_token = self.lexer.get_next_token()
else:
self.error()
def factor(self):
current_token = self.current_token
if current_token.value_type == INTEGER:
self.eat(INTEGER)
return Num(current_token) # 返回数字节点对象
elif current_token.value_type == LPAREN:
self.eat(LPAREN)
node = self.expr() # # 创建运算符节点对象
self.eat(RPAREN)
return node # 返回运算符节点对象
def term(self):
node = self.factor() # 左侧节点对象
while self.current_token.value_type in (MUL, DIV):
token = self.current_token
if token.value_type == MUL:
self.eat(MUL)
elif token.value_type == DIV:
self.eat(DIV)
node = BinaryOperator(node, token, self.factor()) # 创建运算符节点对象
return node # 返回节点对象
def expr(self):
node = self.term() # 左侧节点对象
while self.current_token.value_type in (PLUS, MINUS):
token = self.current_token
if token.value_type == PLUS:
self.eat(PLUS)
elif token.value_type == MINUS:
self.eat(MINUS)
node = BinaryOperator(node, token, self.term()) # 返回二元运算表达式的节点
return node # 返回运算符节点对象
def parser(self): # 定义语法分析器的方法
return self.expr() # 返回树对象
五、定义解释器类
理解AST的构造过程非常重要,就好像前一张图片中演示的“2 * 7 + 3”这个表达式的AST构造过程。
构造的顺序是从左至右的。
练习:模拟一下语法分析器为算术表达式“7 + 3 * (10 / (12 / (3 + 1) – 1))”建立AST的过程。
马上给出答案:
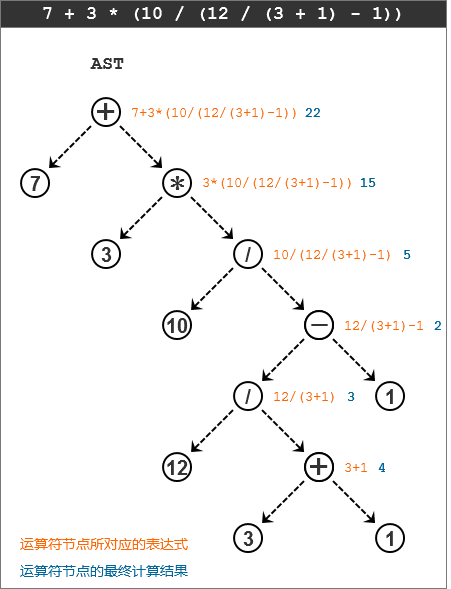
树的遍历过程,是从根节点开始,然后按照“左–>右–>根”的顺序递归完成节点访问。
这种遍历方法叫做后序遍历,它是深度优先遍历的一种。
我们看一段伪代码:
def visit(node):
# 从左至右的遍历每一个节点的子节点
for child in node.childen:
visit(child) # 递归
<< 后置动作 >>
我们使用后序遍历的原因是:
首先,我们需要对树中的内部节点先进行计算,因为它们具有较高优先级的操作符;
其次,我们需要在将操作符应用到子节点中的操作数之前,先获取子节点中操作符节点的运算结果。
就像之前的例子,算术表达式“ 2 * 7 + 3”的AST中,“*”是“+”的子节点,我们如果想让“+”完成运算,它的前提是“*”的节点已经有了运算结果。
深度优先遍历有三种类型:前序遍历、中序遍历和后序遍历。
遍历方法的名称来自于在访问代码中放置操作的位置:(伪代码)
def visit(node):
<< 前置动作 >> # 前序遍历:根-->左-->右
left_val = visit(node.left) # 访问左侧子节点
<< 内部动作 >> # 中序遍历:左-->根-->右
left_val = visit(node.right) # 访问右侧子节点
<< 后置动作 >> # 后序遍历:左-->右-->根
接下来,我们编写代码来访问和解释由语法分析器构建的AST。
1、定义节点访问器类,这个类是解释器类的基类。
在这个类中定义一个泛型方法,用于访问不同类型的节点。
示例代码:
class NodeVisitor: # 定义节点访问器的类
def visit(self, node): # 定义访问方法
method_name = 'visit_' + type(node).__name__ # 获取节点类型名称组成访问器方法名(子类Interpreter中方法的名称)
visitor = getattr(self, method_name, self.generic_visit) # 获取访问器对象,找不到访问器时获取“generic_visit”方法对象。
return visitor(node) # 返回访问器访问节点的结果
def generic_visit(self, node): # 定义通用访问方法
raise Exception(f'未找到“visit_{type(node).__name__}()”方法!') # 抛出异常
2、修改解释器类,继承自节点访问器类。
在解释器类中,我们实现各种节点类型的访问方法。
class Interpreter(NodeVisitor): # 定义解释器类(继承节点访问器类)
def __init__(self, parser): # 初始化方法
self.parser = parser # 接收语法分析器对象
def visit_BinaryOperator(self, node): # 访问二元运算符类型节点的方法
if node.operator.value_type == PLUS: # 如果操作符类型是加法
return self.visit(node.left) + self.visit(node.right) # 分别访问左侧和右侧的记号,将获取的值进行加法运算,并返回结果。
elif node.operator.value_type == MINUS:
return self.visit(node.left) - self.visit(node.right)
elif node.operator.value_type == MUL:
return self.visit(node.left) * self.visit(node.right)
elif node.operator.value_type == DIV:
return self.visit(node.left) // self.visit(node.right)
def visit_Num(self, node): # 访问数字类型节点的方法
return node.value
def interpret(self): # 执行解释的方法
tree = self.parser.parser() # 获取语法分析器分析后的树对象
return self.visit(tree) # 返回访问树对象的计算结果
这里有两个关键点:
第一,操作AST节点的访问者代码与AST节点本身解耦。
我们可以看到,AST节点类(BinaryOperator和Num)中没有编写任何代码去操作存储在这些节点中的数据。
运算逻辑封装在实现NodeVisitor类的解释器类中。
第二、NodeVisitor中的访问方法使用了泛型,而不是通过条件判断确定类型。
示例代码:(条件判断)
def visit(node):
node_type = type(node).__name__
if node_type == 'BinOp':
return self.visit_BinaryOperator(node)
elif node_type == 'Num':
return self.visit_Num(node)
elif ...
示例代码:(条件判断)
def visit(node):
if isinstance(node, BinOp):
return self.visit_BinaryOperator(node)
elif isinstance(node, Num):
return self.visit_Num(node)
elif ...
注意:以上是我们没有使用的两种访问方法。
花一些时间研究这种方法(标准Python模块AST使用相同的机制来进行节点遍历),因为我们将在之后扩展我们的解释器,编写许多新的visit_NodeType方法。
另外,generic_visit访问方法是引发异常的方法,当遇到一个节点,而解释器类中没有实现相应的visit_NodeType方法时,此方法被调用。
六、修改主函数
因为增加了语法分析器类并重写了解释器类,所以主函数需要进行相应的修改。
示例代码:
def main():
while True:
try:
text = input('SPI>>>') # 改个样式,看着更专业一些:)
except EOFError:
break
if not text:
continue
lexer = Lexer(text)
parser = Parser(lexer) # 传入词法分析器对象实例化语法分析器
interpreter = Interpreter(parser) # 传入语法分析器对象实例化解释器
result = interpreter.interpret() # 解释器对象调用解释方法获取结果
print(text, '=', result)
当完成以上的内容,我们可以运行程序,查看程序是否能够正常的帮我们进行运算。
这里是一些测试:
SPI>>> 7 + 3 * (10 / (12 / (3 + 1) - 1))
22
SPI>>> 7 + 3 * (10 / (12 / (3 + 1) - 1)) / (2 + 3) - 5 - 3 + (8)
10
SPI>>> 7 + (((3 + 2)))
12
到这里,我们已经了解了解析树、AST、如何构造AST以及如何遍历AST来解释那些AST所表示的输入。
我们还修改了语法分析器和解释器,并将它们拆分为独立的类。
现在,Lexer、Parser和Interpreter之间的联系看起来是这样的:

可以理解为:“语法分析器器从词法分析器中获取记号,然后返回生成的AST,由解释器来遍历和解释输入。”
最后,我们再来简单了解一下递归下降语法分析器(Recursive-Descent Parser)的定义:递归下降语法分析器是一个自顶向下的解析器,它通过一组递归过程来处理输入。自顶向下反映了语法分析器通过构造解析树的顶部节点然后逐步构造较低位置节点的情形。
以下是本篇文章的练习:
- 编写一个节点访问器,把算术表达式作为输入并用后缀表达式打印出来,也称为逆波兰记法(Reverse Polish notation:RPN)。例如,如果输入的表达式是“( 5 + 3 ) * 12 / 3”,则输出应该是“5 3 + 12 * 3 /”。先尝试解决,然后再参考【答案】(本站答案在评论1楼)。
- 编写一个节点访问器,把算术表达式作为输入并用LISP风格表示法打印出来。例如,“2 + 3”输出“( + 2 3 )”,“( 2 + 3 × 5 )”输出“( + 2 ( * 3 5 ) )”。先尝试解决,然后再参考【答案】(本站答案在评论1楼)。
而且,当学习完这篇文章,请大家自我检查一下,是否了解了以下内容:
- 什么是树(Tree)?
- 什么是解析树(Parse Tree)?
- 什么是抽象语法树(AST)?
- 解析树与抽象语法树的区别有哪些?
- 遍历方式有哪几种?遍历方式的名称取决于什么?
- 什么是递归下降解释器?
在下一篇文章中,我们将会向解释器中添加赋值和一元运算符。
项目源代码下载:【点此下载】
转载请注明:魔力Python » 一起来写个简单的解释器(7)
# 练习1 def visit_BinaryOperator(self, node): return f'{self.visit(node.left)} {self.visit(node.right)} {node.operator.value}' # 练习2 def visit_BinaryOperator(self, node): return f'({node.operator.value} {self.visit(node.left)} {self.visit(node.right)})'