本系列文章参考国外编程高手鲁斯兰的博客文章《Let’s Build A Simple Interpreter》。
“Be not afraid of going slowly; be afraid only of standing still.” – Chinese proverb.
上面这句英文来自鲁斯兰的博客,很有趣的是,这是一句中国谚语:不怕慢,就怕站。
意思就是说,不怕你学的慢,只要向前就总会离完成目标越来越近,就怕你停滞不前,那就永远没有了达成目标的希望。
我想说:如果你已认清自己具备学习编程语言的能力,并开始学习Python这门语言,那么请你不抛弃、不放弃,你最终会有收获。
关于鲁斯兰,我在领英上了解了他的一些个人信息。
他是一个团队的负责人,喜欢多种编程语言,热衷于学习并帮助团队一起学习,提高工作能力。
他有着非常优秀的人格魅力,他的前任和现任上司以及同事都对他非常尊重和肯定。
我想这种人格魅力的形成,得益于他对工作、学习以及生活的态度,我想这值得我们每一个人学习。
好了,接下来我们进入正题。
这篇文章,我们一起来完成对过程声明(Procedure Declaration)的解析。
过程声明是定义标识符(过程名称)并将其与一个Pascal代码块关联的语言构造。
我们来看一段Pascal代码。
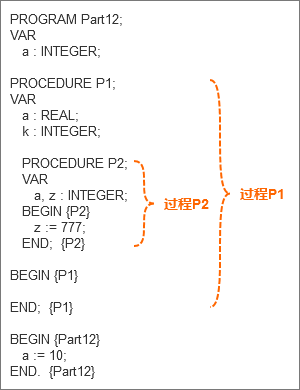
在上图的代码中,我们能够看到声明部分包含了过程声明。
语句“PROCEDURE P1;”是过程的开始标记和名称。
在这条语句下方和最后一组“BEGIN…END”之前的所有语句就是过程的代码块。
并且,我们还能看到在过程P1的声明部分还嵌套了过程P2。
那么,如何解析这样的代码呢?
一、更新文法
过程声明的出现需要体现在新的文法中。
我们能够看到,过程声明是声明的一部分。
所以,需要更新的文法,也只是声明的规则。
新的声明规则如下:
declarations : VAR (variable_declaration SEMI)+ | (PROCEDURE ID SEMI block SEMI)* | empty
在原来的文法中,我们添加了对过程声明的内容。
因为,程序中可能包含一个或多个过程声明,也可能一个都没有。
所以,过程声明的文法放在了“()*”中。
在新增加的内容中,“PROCEDURE”是保留字,“ID”是名称,其他的大家都已见过。
二、添加常量
根据新的文法,我们需要将保留字“PROCEDURE”声明为常量。
示例代码:
PROCEDURE = 'PROCEDURE' # 过程
三、更新词法分析器(Lexer)
“PROCEDURE”作为保留字需要添加到保留字的字典中,并映射为过程的的记号对象。
示例代码:
RESERVED_KEYWORDS = {
'PROGRAM': Token('PROGRAM', 'PROGRAM'),
'PROCEDURE': Token('PROCEDURE', 'PROCEDURE'), # 保留字
...省略其它代码...
}
四、更新语法分析器(Parser)
1、添加AST节点
过程声明由名称和代码块组成。
示例代码:
class ProcedureDecl(AST): # 添加过程声明节点
def __init__(self, name, block_node):
self.name = name # 名称
self.block_node = block_node # 块节点
2、修改声明的方法
在声明的方法中,添加过程声明的代码,实现过程声明节点的创建。
示例代码:
def declarations(self): # 修改创建声明节点的方法
declarations = []
if self.current_token.value_type == VAR:
self.eat(VAR)
while self.current_token.value_type == ID:
declarations.extend(self.variable_declaration())
self.eat(SEMI)
while self.current_token.value_type == PROCEDURE: # 当前记号类型是过程时
self.eat(PROCEDURE) # 验证过程类型
procedure_name = self.current_token.value # 获取过程名称
self.eat(ID) # 验证过程名称
self.eat(SEMI) # 验证分号
block_node = self.block() # 获取过程中的块
procedure_decl = ProcedureDecl(procedure_name, block_node) # 由过程名称和块组成过程声明对象
declarations.append(procedure_decl) # 声明列表末尾添加新的过程声明
self.eat(SEMI) # 验证分号
return declarations
五、更新符号表生成器
因为还没有完成处理过程的相关准备,我们先在符号表生成器中添加一个空的方法,在之后的文章中完善它。
示例代码:
def visit_ProcedureDecl(self, node): # 定义访问过程声明的方法
pass
六、更新解释器
和符号表生成器中一样,我们暂时还不能对过程进行解释,这里同样添加一个空的方法。
示例代码:
def visit_ProcedureDecl(self, node): # 添加访问过程声明的方法
pass # 暂不处理
当我们完成以上步骤,就完成了本文内容涉及到的代码修改。
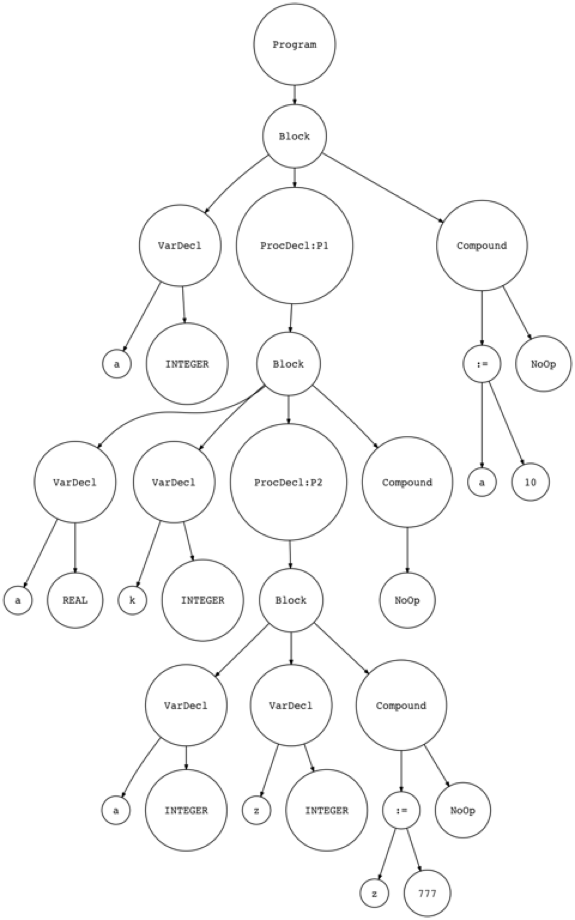
基于这些修改,我们来看一下程序的抽象语法树是什么样子的。
以下面这段Pascal代码为例:
PROGRAM Part12;
VAR
a : INTEGER;
PROCEDURE P1;
VAR
a : REAL;
k : INTEGER;
PROCEDURE P2;
VAR
a, z : INTEGER;
BEGIN {P2}
z := 777;
END; {P2}
BEGIN {P1}
END; {P1}
BEGIN {Part12}
a := 10;
END. {Part12}
这段程序的抽象语法树如下图所示:
然后,我们通过解释器对上方这段Pascal程序进行解释。
之前,为了方便,我都是将Pascal程序代码写到了主程序函数中。
在这里,我们采用鲁斯兰的原有做法,将Pascal程序保存为“.pas”的文件,然后通过Python命令进行解释。
所以,需要修改一下主程序。
示例代码:
def main():
import sys
text = open(sys.argv[1], 'r').read() #打开系统命令中的第二个参数(Pascal文件)并读取内容
lexer = Lexer(text)
...省略其它代码...
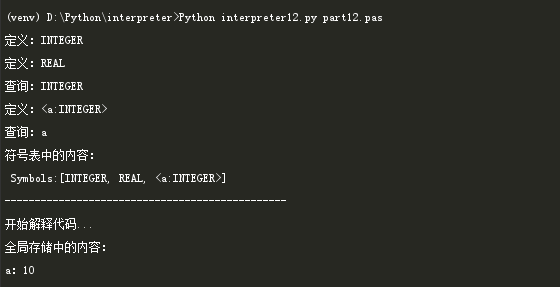
修改完主程序之后,打开命令行窗口,输入命令进行测试。
测试结果如下:
最后,说明一下。
在我们的知识和经验的基础上,我们已经准备好了处理嵌套域的学习。
我们需要透彻理解这篇文章所讲到的内容,以便能够分析嵌套过程并准备好处理过程和函数调用。
在下一篇文章中我们将深入嵌套作用域的学习。
项目源代码下载:【点此下载】
转载请注明:魔力Python » 一起来写个简单的解释器(12)