本系列文章参考国外编程高手鲁斯兰的博客文章《Let’s Build A Simple Interpreter》。
在这个系列文章的最后四篇(第14-17部分)文章中,我们将学习到以下内容:
- 第14部分:嵌套作用域(Nested scopes)
- 第15部分(尚未发布):过程调用(Procedure calls)、运行时(Run-time)、调用堆栈(Call stack)
- 第16部分(尚未发布):类型检查(Type checking)
- 第17部分(尚未发布):交互式调试器(Interactive debugger)
提示:鲁斯兰的博客已有一年多未更新,最后三篇文章一直未能发布。不过,即便不完整,在这个过程中我们仍然能学习到很多内容,建议大家坚持学完现有的14部分。
在上一篇文章末尾提到在这一篇文章中进行嵌套作用域的学习。
不过,在深入域的学习之前,还需要再进行一些关于符号、符号表以及语义分析的学习。
这些内容有助于我们建立更扎实的基础以便更好的学习嵌套作用域。
在这篇文章中,我们继续扩展关于编写解释器和编译器的知识,其中的所涉及的部分内容是基于第11篇文章的扩展,主要关于符号与符号表。
一、语义分析
虽然我们的Pascal程序符合文法规则,并且能够通过语法分析器(Parser)构建一个抽象语法树(AST),但是,程序仍然可以包含一些相当严重的错误。为了捕获这些错误,我们需要使用抽象语法树(AST)和符号表(Symbol Table)中的信息。
为什么不能在语法分析过程中解决这些错误,而是需要构建抽象语法树(AST)和符号表呢(Symbol Table)?
简单来说是为了方便和分离关注点(Separation of Concerns)。
提示:模块化软件开发就是一种分离关注点(Separation of Concerns)的手段。
通过将这些额外的检查独立出来,我们就可以一次专注于一个任务,而不需要增加解释器的负担(或者说复杂性)。
当语法分析器完成AST的构建时,我们能够确定程序是语法是正确的,也就是说,程序的语法符合我们的文法规则。
然后,我们就可以单独关注错误检查,那些因为没有附加上下文信息,从而在语法分析器构建AST时无法捕获的错误。
为了更直观的理解,我们看一个Pascal程序的赋值语句:
x := x + y;
语法分析器会对上方的语句进行处理,因为语法是正确的。
但是Pascal有一个要求:在使用变量之前,必须用相应的类型声明变量。
那么,语法分析器如何知道变量“x”和“y”是否已经声明?
显然语法分析器自身是无法做到的。
这就是为什么我们需要一个单独的语义分析(Semantic Analysis)阶段来回答变量是否在使用之前被声明过的问题。
所以,语义分析基本上是一个过程,帮助我们确定程序是否有意义,并且符合语言定义。
对于一个程序,语法分析意味着什么,很大程度上取决于语言定义和语言要求。
Pascal语言,特别是Free Pascal编译器有一些具体的要求,如果程序中没有遵循这些要求,则会导致FPC编译器错误,表示程序“无意义”。哪怕语法看来来没有问题,也是不正确的。
以下是一些相关的要求:
- 变量在使用之前必须声明。
- 变量在算术表达式中使用时必须具有匹配类型(这是语义分析的一大部分,我们称之为类型检查)。
- 不应该有重复声明(Pascal中严格禁止,例如,过程中定义的局部变量与过程的形式参数命名相同即为重复声明)。
- 调用过程时引用的名称必须是指向一个已经实际声明的过程(例如在过程中调用foo(),而“foo”这个的名称指向了一个原始类型为整数的变量foo,那么,在Pascal中就没有意义了)。
- 过程调用必须具有正确的参数数数量,并且参数类型必须与过程声明中的形式参数相匹配。
当我们拥有足够的程序上下文,就能够非常容易的执行上面的要求。
或者说,拥有一个AST形式的中间表示和能够访问的具有不同程序实体信息(像变量、过程和函数)的符号表。
在我们实现语义分析阶段之后,我们的Pascal解释器的结构将是这样的:
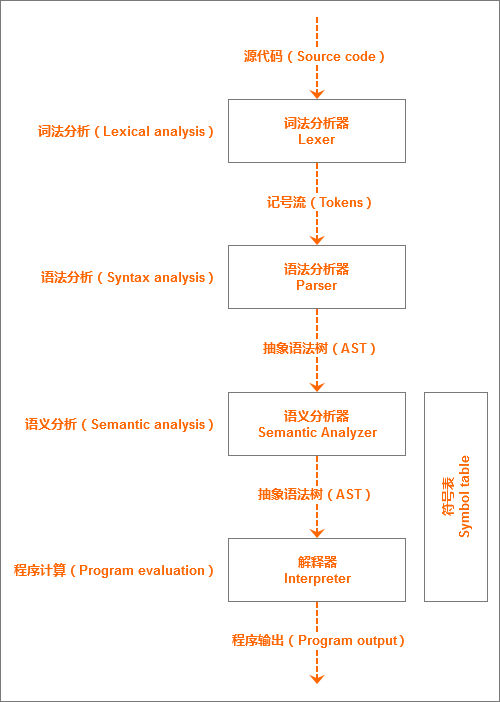
从上图我们可以看到:
- 词法分析器获取源代码作为输入,将源代码转换为语法分析器能够使用的记号;
- 语法分析器消耗使用记号,并用于验证程序符合文法规则,然后生成一个AST;
- 在新的语义分析阶段使用AST,执行不同的Pascal语言要求;
- 在语义分析阶段,语义分析器也将建立和使用符号表;
- 在语义分析之后,解释器访问AST来执行运算,并产生程序输出。
二、符号和符号表
以下内容涉及到语义分析的细节。
我们共同学习如何实现一些语义检查和符号表的构建,执行对Pascal程序的语义分析。
语义分析是解析程序并创建AST来检查源程序的一个步骤,目的是检查由于缺少附加信息(上下文),解析器无法捕获的一些附加错误。
这里我们将重点讨论以下两个静态语义检查:
- 变量必须在使用前声明;
- 不能有重复的变量声明。
静态语义检查是我们在解释程序之前,即在解释器类的实例调用解释方法之前所做的检查。前面提到的所有Pascal程序要求都可以通过使用AST和来自符号表的信息执行静态语义检查。
动态语义检查是指在程序的解释过程中执行检查。例如,零除和数组索引超出界限的错误检查是动态语义检查。
在这篇文章中,我们只会接触到静态语义检查。
第1个检查:变量必须在使用前声明。
示例代码:
program Main;
var x : integer;
begin
x := y;
end.
上方代码中的错误是显而易见的,有两个变量“x”和“y”被引用,但只有一个变量“x”被声明,变量“y”在使用前没有经过声明。
我们用之前写好的解析器来解析这段代码:
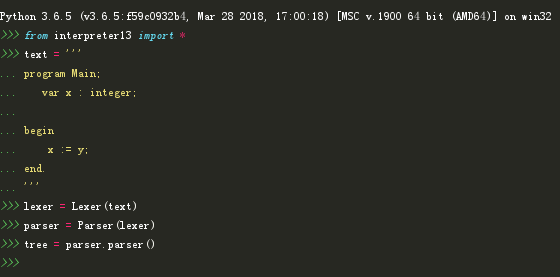
执行解析方法之后,没有发生任何错误。
所以,像这样的程序语法上虽然正确,但却没有意义,因为程序的语义是错误的。
为了能够在解释器解释程序之前捕捉到这样的错误,我们需要进行语义分析。
我们再来看一段代码:
program Main;
var x, y : integer;
begin
x := x + y;
end.
在上方代码中,复制语句“x := x + y;”引用了3个变量,分别是“x”,另外一个“x”和“y”。
并且,变量“x”和“y”都已声明为整数类型。
那么,上方这段代码是一段语法和语句都正确的代码。
但是,这是我们人为检查的结果。
我们如何通过编写的代码完成这个检查呢?
通过以下算法的4个步骤能帮助我们达成目标:
- 遍历所有变量声明;
- 遇到变量声明时,收集关于变量声明的所有必要信息进行存储;
- 将所有收集的信息存储到某个存储区,并以变量名称为键值作为之后的引用;
- 当遇到一个变量引用,就用变量的名称在存储区进行查询,查看存储区是否有关于该变量的任何信息;如果存在相关信息,视变量为已声明的变量,否则就是未声明变量(即语义错误)。
为了更容易理解,大家可以同时参考下方的算法流程图:
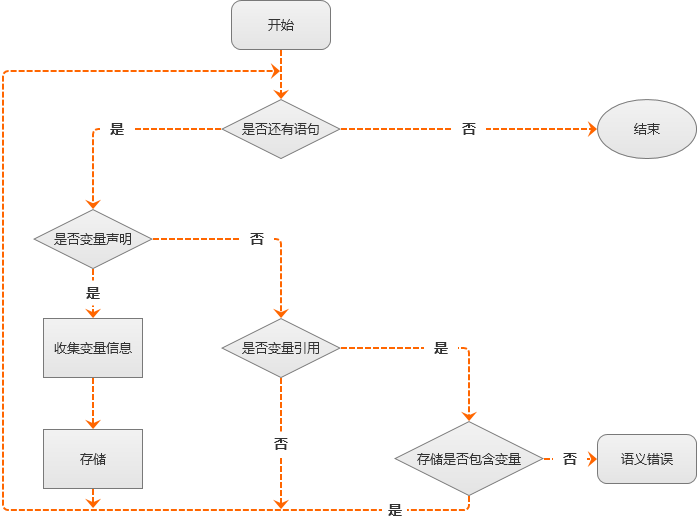
在我们实现算法之前,需要先解决三个问题:
- 我们需要收集的关于变量的信息是什么?
- 我们需要在哪里以怎样的方式存储信息?
- 我们如何完成遍历所有变量声明的步骤?
旁白:我很惊讶居然能把三个问题写的一样长…
接下来,我们就来寻找这三个问题的答案。
1、我们需要收集的关于变量的信息是什么?
实际上在我们刚刚接触到符号的时候,就已经了解到3个信息:名称、类别和类型。
名称:我们需要知道变量的名称,然后能够通过名称查找变量。
类别:我们需要知道标识符的类型,例如:变量、类型和过程等。
类型:我们需要通过类型信息进行类型检查。
符号保存了这3个信息。
这里,我们重温一下符号的定义:符号是一些程序实体的标识符,如变量、子程序或内置类型。
在已经写过的代码中,我们通过一个符号类来表示符号,符号具有名称和类型。
示例代码:
class Symbol:
def __init__(self, name, symbol_type=None):
self.name = name
self.symbol_type = symbol_type
那么,类别呢?
我们可以在代码中添加类别。
示例代码:
class Symbol:
def __init__(self, name, symbol_type=None):
self.name = name
self.symbol_type = symbol_type
self.category = category
不过,我们不需要这样做。
我们可以直接通过类的名称指示其类别。
以内置类型符号为例(注意内置类型符号没有类型)。
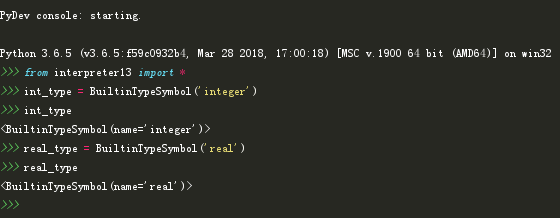
示例代码:(interpreter13.py)
class BuiltinTypeSymbol(Symbol):
def __init__(self, name):
super().__init__(name)
def __str__(self):
return self.name
def __repr__(self):
return f"{self.__class__.__name__}(name='{self.name}')" # 输出类名和符号名称
打开Python Shell我们做一下测试:
我们再来看变量符号。
示例代码:(interpreter13.py)
class VarSymbol(Symbol):
def __init__(self, name, symbol_type):
super().__init__(name, symbol_type)
def __str__(self):
return f"<{self.__class__.__name__}(name='{self.name}':type='{self.symbol_type}')>" # 输出类名、符号名称和类型
__repr__ = __str__
同样,打开Python Shell进行测试。
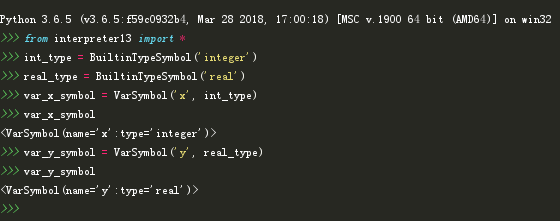
如上所示,我们首先创建内置类型符号的实例,然后将其作为第2个参数传递给变量符号的构造函数。变量符号必须具有与它们相关联的名称和类型。
2、我们需要在哪里以怎样的方式存储信息?
实际上这个答案大家应该都已经知道,那就是符号表。
符号表是用于跟踪源代码中各种符号的抽象数据类型。
把它看作一个字典的话,其中键是符号的名称,值是符号类的实例(或者它的子类之一)。
为了在代码中表示符号表,我们专门创建了一个符号表类。
不过,为了在符号表中存储符号,我们将把插入方法“insert()”添加到符号表类中。
“insert()”方法以符号作为参数,并以符号的名称为键,将符号实例作为值存储在符号表的有序字典中。
示例代码:(symbol01.py)
from collections import OrderedDict
class SymbolTable:
def __init__(self):
self._symbols = OrderedDict()
def __str__(self):
symtab_header = '符号表中的内容:'
lines = [symtab_header, '-' * len(symtab_header) * 2] # 头部标题与分割线存入打印内容的列表
lines.extend([f'{key:8}: {value}' for key, value in self._symbols.items()]) # 符号表内容合并到打印内容列表
s = '\n'.join(lines) # 以换行符连接每个列表元素组成字符串
return s # 返回打印内容
__repr__ = __str__
def insert(self, symbol): # 添加存入符号的方法
print(f'存入:{symbol}')
self._symbols[symbol.name] = symbol # 以符号名称为键存入符号
接下来,我们通过一段测试代码构建符号表,看一下最终的输出结果。
示例代码:(symbol01.py)
from interpreter13 import Lexer, Parser, BuiltinTypeSymbol, VarSymbol
if __name__ == '__main__':
text = """
program SymTab1;
var x, y : integer;
begin
end.
"""
lexer = Lexer(text)
parser = Parser(lexer)
tree = parser.parser()
symtab = SymbolTable()
int_type = BuiltinTypeSymbol('INTEGER')
symtab.insert(int_type)
var_x_symbol = VarSymbol('x', int_type)
symtab.insert(var_x_symbol)
var_y_symbol = VarSymbol('y', int_type)
symtab.insert(var_y_symbol)
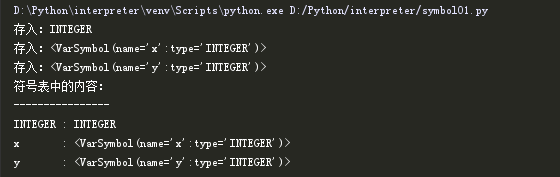
print(symtab)
我们能够看到输出的结果为:
到这里,关于前两个问题我们都得到了答案。
问题1、我们需要收集的关于变量的信息是什么?
答案是名称、类型与类别,我们用符号保存这些信息。
问题2、我们需要在哪里以怎样的方式存储信息?
答案是使用符号表的“insert()”方法将符号存入符号表,以存储收集到的符号。
3、我们如何完成遍历所有变量声明的步骤?
因为,我们已经有了由语法分析器构建的AST,现在只需要再创建一个新的AST访问器类,让它负责访问AST,在遇到VarDecl 节点时做不同的动作。
示例代码:(symbol02.py)
from interpreter13 import Lexer, Parser, NodeVisitor, BuiltinTypeSymbol, VarSymbol
class SemanticAnalyzer(NodeVisitor): # 添加语义分析器
def __init__(self):
self.symbol_table = SymbolTable() # 创建符号表
def visit_Program(self, node): # 添加与访问变量声明相关的访问方法
self.visit(node.block)
def visit_Block(self, node): # 添加与访问变量声明相关的访问方法
for declaration in node.declarations:
self.visit(declaration)
self.visit(node.compound_statement)
def visit_VarDecl(self, node): # 添加访问变量声明的方法
pass # 具体内容见下文
def visit_Compound(self, node): # 添加与访问变量声明相关的访问方法
for child in node.children:
self.visit(child)
def visit_NoOperator(self, node): # 添加与访问变量声明相关的访问方法
pass
上面代码中,已经将所有可能包含变量声明节点的方法添加完毕,接下来,我们专门编写访问变量声明节点的方法。
示例代码:
def visit_VarDecl(self, node): # 添加访问变量声明的方法(1.遍历变量声明节点)
symbol_type = BuiltinTypeSymbol('INTEGER') # 创建内置类型对象
self.symbol_table.insert(symbol_type) # 内置类型符号对象添加到符号表
var_name = node.var_node.name # 获取变量名称(2.收集变量信息)
var_symbol = VarSymbol(var_name, symbol_type) # 创建变量符号对象(2.收集变量信息)
self.symbol_table.insert(var_symbol) # 添加变量符号对象到符号表(3.存入存储区)
实际上,在上方代码中我们已经完成了算法4个步骤中的前3个。
最后,我们编写测试代码进行测试。
示例代码:(symbol02.py)
if __name__ == '__main__':
text = '''
program SymTab2;
var x, y : integer;
begin
end.
'''
lexer = Lexer(text)
parser = Parser(lexer)
tree = parser.parser()
semantic_analyzer = SemanticAnalyzer()
semantic_analyzer.visit(tree)
print(semantic_analyzer.symbol_table)
运行程序后,测试结果如下:
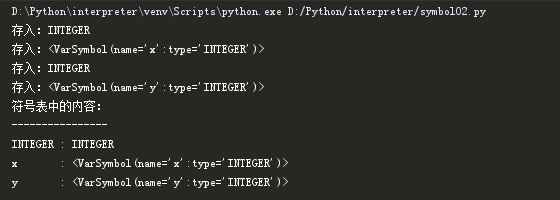
大家可以看到在上方的运行结果中,INTEGER被存入两次,这个问题接下来的代码中就会解决。
我们在前面的步骤中,已经完成了变量信息的收集和存储,当变量被引用时,我们应该能够使用这些信息。
所以,接下来是算法的最后一个步骤:当遇到一个变量引用,就用变量的名称在存储区进行查询,查看存储区是否有关于该变量的任何信息;如果存在相关信息,视变量为已声明的变量,否则就是未声明变量(即语义错误)。
首先,让我们通过添加将按名称搜索符号的查找方法更新符号表类。
换句话说,查找方法负责将变量名(变量引用)解析到其声明。
将变量引用映射到其声明的过程称为名称解析(Name Resolution)。
大家应该还记得在之前文章关于符号表的代码中,我们定义过_init_builtins()方法和lookup()方法,分别用于内置类型初始化和变量的查询。
在我们新构建的符号表类中,也需要这个两个方法。
示例代码:(symbol03.py)
...省略其它代码...
class SymbolTable:
def __init__(self):
self._symbols = OrderedDict()
self._init_builtins() # 初始化内置类型
def _init_builtins(self): # 定义初始化内置类型的方法
self.insert(BuiltinTypeSymbol('INTEGER')) # 通过insert()方法存入内置类型符号
self.insert(BuiltinTypeSymbol('REAL')) # 通过insert()方法存入内置类型符号
...省略其它方法代码...
def lookup(self, name): # 添加查询方法
print(f'查询:{name}')
symbol = self._symbols.get(name)
return symbol
...省略其它代码...
有了lookup()方法之后,内置类型就不需要在AST节点访问方法中存入,所以需要修改visit_VarDecl()方法。
示例代码:
def visit_VarDecl(self, node):
symbol_type = node.type_node.name
self.symbol_table.lookup(symbol_type) # 从符号表查询内置类型符号
var_name = node.var_node.name
var_symbol = VarSymbol(var_name, symbol_type)
self.symbol_table.insert(var_symbol)
我们对修改后的代码进行验证。
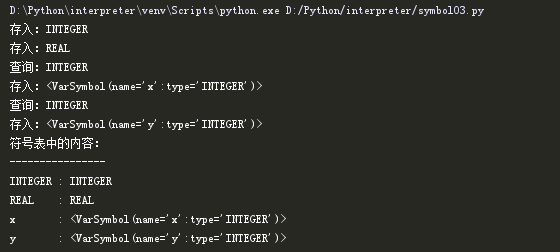
通过上方代码的添加我们已经解决了INTEGER被存入两次的问题,并且能够对符号进行查询。
不过,在之前的测试程序代码中只有变量的声明,接下来,我们在测试代码中加入对变量的引用。
program SymTab4;
var x, y : integer;
begin
x := x + y;
end.
当Pascal程序中出现了对变量的引用,我们该如何处理呢?
首先会想到的是,从符号表中查询被引用的变量名称。
那么,什么时候去进行查询呢?
当语义分析器(SemanticAnalyzer)通过访问方法访问变量的时候,也就是visit_Variable()方法。
示例代码:
def visit_Variable(self, node):
var_name=node.name
var_symbol=self.symbol_table.lookup(var_name)
注意:上方代码中我们只是对引用的变量进行了查询,并没有对查询结果进行处理,这将在后面定义语义错误时进行添加。
然后,我们还要知道,变量的引用可能出现在赋值语句中,也可能出现在运算中,这些节点的访问时必须的,所以要把这些节点的访问方法要添加到语义分析器(SemanticAnalyzer)中。
示例代码:
def visit_BinaryOperator(self, node):
self.visit(node.left)
self.visit(node.right)
def visit_Assign(self, node):
self.visit(node.left)
self.visit(node.right)
测试一下上方的代码:
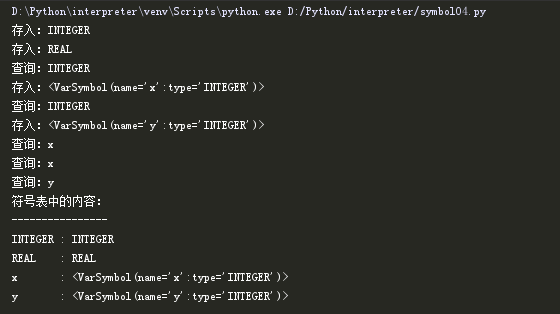
通过上方这些新增代码,我们的语义分析器已经可以进行变量引用的查询处理,验证变量是否在使用前已经声明。
不过,我们还没有对查询结果进行处理,所以没有语义错误的输出。
所以,我们还要增加完成引用变量的查询时,对查询结果进行处理的代码。
示例代码:
def visit_Variable(self, node):
var_name = node.name
var_symbol = self.symbol_table.lookup(var_name)
if var_symbol is None: # 如果变量未声明
raise NameError(f'引用了不存在的标识符:{repr(var_name)}') # 抛出语义错误
接下来,我们使用一个错误的Pascal程序进行测试。
program SymTab5;
var x : integer;
begin
x := y;
end.
程序中的变量“y”未经过声明。
我们在测试代码中捕获异常并显示输出。
示例代码:
if __name__ == '__main__':
from interpreter13 import Lexer, Parser
text = '''
program SymTab5;
var x : integer;
begin
x := y;
end.
'''
lexer = Lexer(text)
parser = Parser(lexer)
tree = parser.parser()
semantic_analyzer = SemanticAnalyzer()
try:
semantic_analyzer.visit(tree)
except Exception as e: # 捕获异常
print(e) # 显示输出异常
print(semantic_analyzer.symbol_table)
测试结果如下:
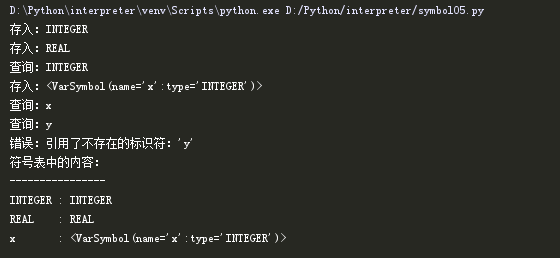
到这里,我们完成了静态语义检查中的第1个检查:变量必须在使用前声明。
第2个检查:不能有重复的变量声明。
既然有了查询变量信息的方法,我们就可以在访问变量声明节点时先进行查询,如果已存在同名变量信息就抛出异常,否则添加变量符号到符号表。
示例代码:
def visit_VarDecl(self, node):
symbol_type = node.type_node.name
self.symbol_table.lookup(symbol_type)
var_name = node.var_node.name
if self.symbol_table.lookup(var_name) is not None: # 查询变量名称,如果存在变量信息
raise Exception(f'错误:发现重复的标识符:{var_name}') # 抛出异常
var_symbol = VarSymbol(var_name, symbol_type)
self.symbol_table.insert(var_symbol)
我们使用一个错误的Pascal程序进行测试。
program SymTab6; var x, y : integer; var y : real; begin x := x + y; end.
这里需要注意,我们之前的Pascal程序都是只有一个“VAR”关键字,分多行声明多个不同类型的变量。
但是在上面这段程序中,出现了多个“VAR”关键字,这就会导致我们之前的声明解析方法出现问题。
所以,我们需要先对声明解析方法进行修改。
示例代码:(interpreter13.py)
class Parser:
...省略其它方法代码...
def declarations(self): # 修改创建声明节点的方法
declarations = []
while True: # 遍历声明
if self.current_token.value_type == VAR: # 如果是变量声明
self.eat(VAR)
while self.current_token.value_type == ID:
declarations.extend(self.variable_declaration())
self.eat(SEMI)
elif self.current_token.value_type == PROCEDURE: # 如果是过程声明
self.eat(PROCEDURE)
procedure_name = self.current_token.value
self.eat(ID)
self.eat(SEMI)
block_node = self.block()
procedure_decl = ProcedureDecl(procedure_name, block_node)
declarations.append(procedure_decl)
self.eat(SEMI)
else: # 否则
break # 结束声明遍历
return declarations
...省略其它方法代码...
完成修改后,我们进行测试,测试结果如下:
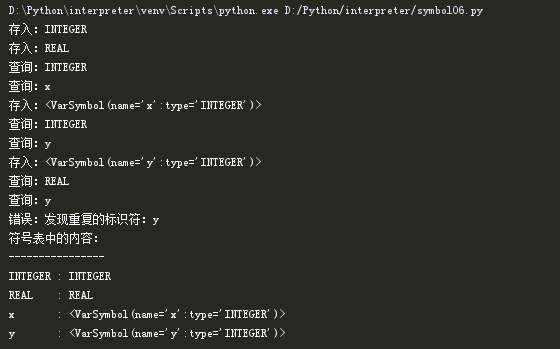
到这里,我们完成了第2个静态语义检查:不能有重复的变量声明。
大家注意,以上实现过程分别写在了6个不同的py文件(symbol01~symbol06)中,我们可以把最终的内容(symbol06)与我们以前写好的程序(interpreter13)进行整合,完善已有的功能。特别注意的是,在新的程序中,语义分析器(SemanticAnalyzer)替代了之前的符号表生成器(SymbolTableBuilder)。
最后,我们做一下总结:
1、我们学习了更多关于符号、符号表和语义分析的知识。
2、我们了解了名称解析以及语义分析器如何解析名称到它们的声明。
3、我们学会了如何编码一个语义分析器,它遍历AST,建立符号表,并进行基本语义检查。
现在,我们的解释器结构如下图所示:
这篇文章我们完成了语义检查,为进入作用域的学习做好了准备。
在下一篇文章中,我们将真正的进入作用域的学习。
项目源代码下载:【点此下载】
转载请注明:魔力Python » 一起来写个简单的解释器(13)