这个练习项目来自《Python基础教程(第2版)》,案例原名为“万能的XML”。
XML是一种可扩展标记语言,具备以下特点(来自百度百科):
- 可扩展标记语言是一种很像超文本标记语言的标记语言。
- 它的设计宗旨是传输数据,而不是显示数据。
- 它的标签没有被预定义,需要自行定义标签。
- 它被设计为具有自我描述性。
- 它是W3C的推荐标准。
上面所说的超文本标记语言,大家已经见过。
一般超文本标记语言就是指HTML。
HTML文件由多个标记(即通常所说的标签)组成。
这些标记通常是成对出现,即一个开始标记对应一个 结束标记。
XML和HTML非常相像,它的标记也是成对出现。
不过,和HTML不同的是,HTML中的标记名称都是固定的,而XML中的标记名称是需要自定义的。
并且,XML和HTML最大不同之处是:XML的目的是传输信息,HTML的目的是显示信息。
例如,一个描述网站结构与页面内容的XML文件。
示例代码:
<website>
<page name="index" title="首页">
<h1>欢迎访问小楼的个人网站!</h1>
<p>您正在访问的是小楼的个人网站,这个网站包含以下内容:</p>
<ul>
<li>
<a href="catalog/articles.html">文章</a>
</li>
<li>
<a href="catalog/downloads.html">下载</a>
</li>
<li>
<a href="catalog/documents.html">文档</a>
</li>
</ul>
</page>
<directory name="catalog">
<page name="articles" title="文章">
<h1>您正在访问文章列表页!</h1>
<p>....</p>
</page>
<page name="downloads" title="下载">
<h1>您正在访问资源下载页!</h1>
<p>...</p>
</page>
<page name="documents" title="文档">
<h1>您正在访问文档列表页!</h1>
<p>....</p>
</page>
</directory>
</website>
在上方XML代码中,通过自定义标记<website>、<directory>以及<page>定义了网站的结构。
并且,通过一些HTML标记,描述了每个网页的内容。
那么,我们就可以通过这个XML文件传输整个网站内容的数据,并通过对XML的解析,生成网站的结构和HTML页面文件。
所以,基于XML传输信息的特点,我们能够通过XML实现很多功能。
如果想很好的掌握XML,还需要深入的学习,请大家自行查阅相关技术文档。【点此查看推荐教程】
对XML有了一些基本的了解之后,我们来看一下如何对XML文件内容进行解析。
首先,我们先来做个小试验。
通过Python内置的xml模块就能够对XML文件进行解析。
这里需要先导入xml模块的一些功能。
示例代码:
from xml.sax import parse from xml.sax.handler import ContentHandler
parse()函数具有解析功能,ContentHandler类则具有内容处理的方法。
ContentHandler类所包含的方法有很多,比较常用的就是对开始元素、内容以及结束元素进行处理的方法。
这些方法,我们需要重写才能够实现我们想要的功能。
在重写方法之前,我们先来看一下通过这个类处理内容时,我们都能获取什么样的内容。
以处理开始标记的方法startElement()为例。
我们创建一个类继承自ContentHandler类,然后重写startElement()方法。
示例代码:
class XMLHandler(ContentHandler):
def startElement(self, name, attrs): # 重写startElement方法
print(name, list(zip(attrs.keys(), attrs.values()))) # 显示输出参数内容
parse('website.xml', XMLHandler()) # 调用解析函数
运行上方代码,我们能够看到以下内容:
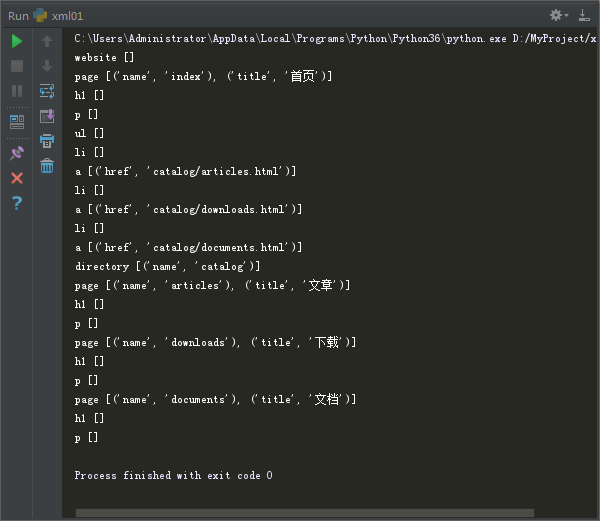
很显然,所有开始标签的名称和属性都能够被获取到。
接下来,我们再进一步,将XML中的每个网页的一级标题(<h1>标签中的内容)提取出来。
为了避免混乱,我们可以删除刚才的代码,重新定义一个类。
示例代码:
class HeadLineHandler(ContentHandler):
def __init__(self, headLines):
super().__init__() # 不写对结果也没有影响
self.headLines = headLines # 初始化类的变量为传入的标题列表
self.in_headLine = False # 初始化开关变量
self.data = [] # 初始化临时保存数据的变量
def startElement(self, name, attrs): # 重写开始元素的方法
if name == 'h1': # 如果是一级标题开始标记
self.in_headLine = True # 打开开关
def characters(self, content): # 重写元素内容的方法
if self.in_headLine: # 如果开关打开
self.data.append(content) # 添加内容到临时变量
def endElement(self, name): # 重写结束元素的方法
if name == 'h1': # 如果是一级标题结束标记
content = ''.join(self.data) # 提取内容为临时变量中保存的所有内容
self.data = [] # 清空临时变量
self.headLines.append(content) # 标题列表中添加提取到的内容
self.in_headLine = False # 关闭开关
if __name__ == '__main__':
headLines = [] # 创建空的一级标题列表
parse('website.xml', HeadLineHandler(headLines)) # 调用解析方法
for line in headLines: # 遍历通过解析写入内容的一级标题列表
print(line) # 显示输出每一个标题内容
运行上方代码,显示结果为:
欢迎访问小楼的个人网站!
您正在访问文章列表页!
您正在访问资源下载页!
您正在访问文档列表页!
代码比较简单,大家参照注释进行理解基本就能够明白整个程序的运行过程。
这里面有两个关键点:
- 变量in_headLine是一个开关,读取到一级标题的开始标记时,打开这个开关,并且将开关打开时读取到的内容提取;当读取到一级标题的结束标记时,关闭这个开关,以免其他内容被提取。
- 变量data是一个临时保存提取内容的列表,在上方代码中并未发挥实际作用,它的作用是将某一对标记之间的多段数据内容顺序保存。只有当一对标记间存在其它标记时,才会出现多段内容,当前练习项目中不存在这种情况。
通过前面两段代码,我们已经对XML解析有了一些了解。
下面,我们就完成解析XML代码并生成HTML页面的功能。
为了避免混乱,我们可以新建一个Python文件。
实现的思路为:
- 读取开始标记时,如果是页面标记(page),创建页面文件,写入页头HTML代码;并打开写入页面内容的开关;
- 读取开始标记时,如果写入页面内容开关被打开,原样写入该开始标记的名称与属性到页面文件;
- 读取标记内容时,如果写入页面内容开关被打开,直接写入内容到页面文件;
- 读取结束标记时,如果是页面标记,关闭写入页面内容的开关,写入页脚HTML代码,关闭页面文件;
- 读取结束标记时,如果写入页面内容开关被打开,直接写入结束标记。
示例代码:
from xml.sax import parse
from xml.sax.handler import ContentHandler
class MakePages(ContentHandler):
in_page = False # 定义开关变量
def startElement(self, name, attrs): # 重写开始元素的方法
if name == 'page': # 如果是页面标记
self.in_page = True # 打开开关
self.file = open(attrs['name'] + '.html', 'w') # 创建HTML文件
self.file.write('<html>\n<head>\n<meta charset="gbk">\n<title>{}</title>\n</head>\n<body>\n'
.format(attrs['title'])) # 写入页头HTML代码
elif self.in_page: # 如果开关被打开
self.file.write('<' + name) # 写入标记开始符号与名称
for key, value in attrs.items(): # 遍历属性集合
self.file.write(' {}="{}"'.format(key, value)) # 写入属性的键值
self.file.write('>') # 写入标记末尾符号
def characters(self, content): # 重写元素内容的方法
if self.in_page: # 如果开关被打开
self.file.write(content) # 写入内容
def endElement(self, name): # 重写结束元素的方法
if name == 'page': # 如果是页面标记
self.in_page = False # 关闭开关
self.file.write('\n</body>\n</html>\n') # 写入页脚HTML代码
self.file.close() # 关闭创建的页面文件
elif self.in_page: # 如果开关被打开
self.file.write('</' + name + '>') # 写入结束标记
if __name__ == '__main__':
parse('website.xml', MakePages()) # 调用解析函数
运行以上代码后,虽然会在项目文件夹中出现4个html文件,但是明显和我们的预期结果不一样。
我们希望能够将除了“index.html”页面之外的页面放在名为“catalog”目录中。
那么,如何解决这个问题呢?
在下一篇教程中,我带大家一起再次实现这个功能,让它能够完美实现。
本节练习源代码:【点此下载】
转载请注明:魔力Python » 练习项目05:解析XML(上)