这一篇教程,我们一起采用一种更复杂,但是更具有扩展性、更易维护的方式来实现新闻采集的功能。
在上一篇教程中,已经提到我们会分别对NNTP服务器的新闻内容以及网页中的新闻内容进行获取,并且以不同的格式输出。
新闻的来源有两种:
- NNTP服务器(web.aioe.org)的新闻组(comp.lang.python)
- 36Kr网站上的新闻快讯(http://36kr.com/newsflashes)
大家可以通过上一篇教程的代码,以及访问上方36Kr的网页地址了解来源的不同形式。
最终输出的目标格式也有两种:
- Print显示输出
- HTML文件
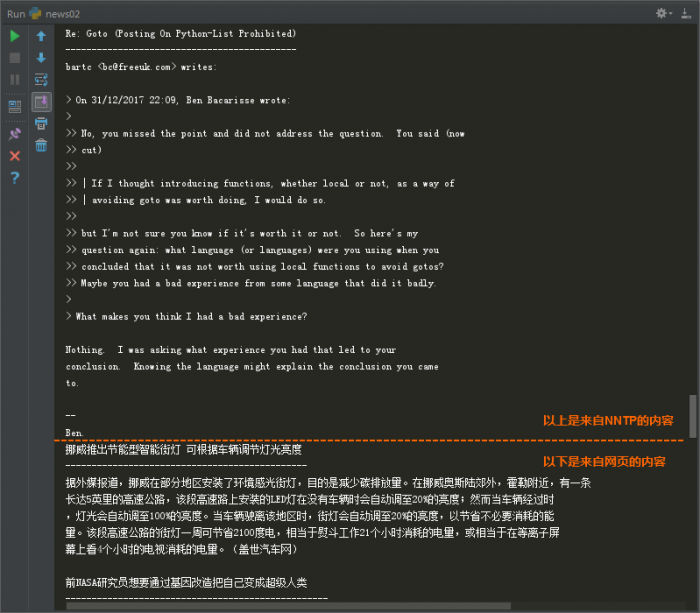
目标格式下方图片所示。
Print显示输出:
HTML文件:
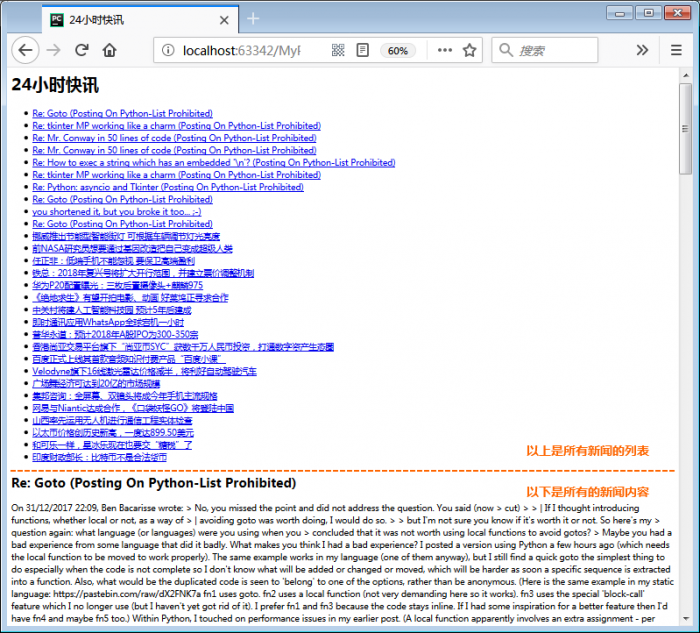
通过上方两张图片,大家能够看出,我们是从两个新闻源获取到新闻内容并混合到一起,采用不同的格式输出这些新闻内容。
为了清晰的实现这个功能,我们先进行一下结构的划分:
- 新闻来源类型(NNTP来源类和Web来源类)
- 新闻内容(新闻类)
- 报告类型(普通显示输出类和HTML文件输出类)
- 处理过程(代理类)
- 主程序
根据不同类的功能,我们能够看到有明确的分层。
- 不同的新闻来源构成后端
- 不同的输出类型构成前端
- 处理过程代理类是中间层
最终,通过主程序将这些具有不同功能的类结合到一起,共同实现目标功能。
1、添加需要使用的模块
在实现这个功能的过程中,我们需要用到很多模块。
示例代码:
from datetime import date, timedelta from nntplib import NNTP from email import message_from_string from urllib.request import urlopen import re, textwrap
上面这些模块,在之后的使用中,大家能够看到它们的用途,这里不再一一介绍。
2、定义类和主程序
根据上面结构的划分,我们编写的代码中,需要完成以下类和主程序的编写。
示例代码:
class NewsItem: # 新闻内容类
pass
class NNTPSource: # NNTP新闻源类
pass
class SimpleWebSource: # 网页新闻源类
pass
class PlainDestination: # 普通输出目标类
pass
class HTMLDestination: # HTML文件目标类
pass
class NewsAgent: # 新闻代理类
pass
def runDefaultSetup(): # 主程序
pass
3、定义处理每行新闻内容宽度的方法
我们在普通输出目标时,新闻内容的每一行都应该有固定的宽度。
所以,我们可以先定义一个处理内容宽度的方法。
示例代码:
def wrap(string, width=50): # 定义处理字符串宽度的方法
return '\n'.join(textwrap.wrap(string, width)) + '\n' # 返回处理之后的结果
4、各个类的实现
(1)新闻内容类
首先,需要定义一条新闻包含的内容:标题和新闻主体。
另外,在普通输出目标时,标题和主体之间要使用横线“—–”进行分隔,横线的数量取决于字符的数量。
但是,中文和英文字符宽度不一样,在显示时,一个英文字符占一个字节宽度,而一个中文字符占两个字节宽度。
所以,在这个类中,我们还需要定义一个字符的字节数量,默认一个字符的字节数量为1。
示例代码:
class NewsItem: # 新闻内容类
def __init__(self, title, body, byteNumber=1):
self.title = title # 新闻标题
self.body = body # 新闻主体
self.byteNumber = byteNumber # 每个字符的字节数量
(2)NNTP新闻源类
这个类,我们需要实现从NNTP服务器的新闻组获取新闻源并将每一条新闻生成的方法。
因为获取到的新闻数量比较多,在这里,我限制了获取数量为前10条新闻。
具体实现过程,大家通过代码中的注释进行理解。
示例代码:
class NNTPSource: # NNTP新闻源类
def __init__(self, server_name, group, window):
self.server_name = server_name # 服务器地址
self.group = group # 新闻组名称
self.window = window # 时间窗口
def getItems(self): # 新闻生成器
yesterday = date.today() - timedelta(days=self.window) # 计算新闻获取的起始时间
server = NNTP(self.server_name) # 创建服务器连接对象
ids = server.newnews(self.group, yesterday)[1] # 获取新闻id列表
count = 0 # 创建计数变量
for id in ids: # 循环获取新闻id
count += 1 # 计数递增
if count <= 10: # 如果计数小于10
article = server.article(id)[1][2] # 获取指定id的新闻文章
lines = [] # 创建每行新闻内容的列表
for line in article: # 从新闻文章中读取每一行内容
lines.append(line.decode()) # 将每行新闻内容解码,添加到新闻内容列表。
message = message_from_string('\n'.join(lines)) # 合并新闻列表内容为字符串并转为消息对象
title = message['subject'].replace('\n', '') # 从消息对象中获取标题
body = message.get_payload() # 从消息对象中获取到新闻主体内容
if message.is_multipart(): # 如果消息对象包含多个部分
body = body[0] # 获取到的内容中第1个部分获取新闻主体内容
yield NewsItem(title, body) # 生成1个新闻内容对象
else: # 如果超出10条内容
break # 跳出循环
server.quit() # 关闭连接
(3)网页新闻源类
这个类,我们需要实现从指定网页获取新闻源并将每一条新闻生成的方法。
具体实现过程,大家通过代码中的注释进行理解。
示例代码:
class SimpleWebSource: # 网页新闻源类
def __init__(self, url, titlePattern, bodyPattern):
self.url = url # 网页地址
self.titlePattern = re.compile(titlePattern) # 提取新闻标题的正则表达式
self.bodyPattern = re.compile(bodyPattern) # 提取新闻主体内容的正则表达式
def getItems(self): # 新闻生成器
text = urlopen(self.url).read().decode() # 读取目标网页内容并解码
titles = self.titlePattern.findall(text) # 通过正则表达式获取所有新闻标题
bodies = self.bodyPattern.findall(text) # 通过正则表达式获取所有新闻主体内容
for title, body in zip(titles, bodies): # 将新闻标题和内容混合到一起并获取每1条新闻的标题和主体内容
yield NewsItem(title, wrap(body), 2) # 生成1个每行新闻具有指定宽度并且每个字符宽度为2个字节的新闻内容对象
(4)普通输出目标类
这个类,我们显示输出新闻对象列表中每1条新闻的标题、分隔线和主体内容。
示例代码:
class PlainDestination: # 普通输出目标类
def receiveItems(self, items): # 定义接收到新闻对象时的处理方法
for item in items: # 遍历新闻对象列表
print(item.title) # 显示输出新闻标题
print('-' * item.byteNumber * len(item.title)) # 显示输出分隔线
print(item.body) # 显示输出新闻主体内容
(4)HTML文件目标类
这个类,我们将新闻对象列表中的所有新闻标题生成HTML文件中的新闻标题列表,并且在HTML文件中写入每1条新闻的标题和主体内容。
具体实现过程,大家通过代码中的注释进行理解。
示例代码:
class HTMLDestination: # HTML文件目标类
def __init__(self, filename):
self.filename = filename # 创建的HTML文件名称
def receiveItems(self, items): # 定义接收到新闻对象时的处理方法
with open(self.filename, 'w', encoding='UTF-8') as file: # 打开或创建HTML文件
file.write('<html>\n' # 写入HTML文件头部内容、网页主体中的标题以及新闻列表的开始标签
'<head>\n'
'<meta charset="UTF-8">\n' # 注意:需要声明网页文件的编码类型
'<title>24小时快讯</title>\n'
'</head>\n'
'<body>\n'
'<h1>24小时快讯</h1>\n'
'<ul>\n')
id = 0 # 初始化HTML文件中的新闻id
for item in items: # 遍历新闻对象集合
id += 1 # 递增新闻id
file.write('<li><a href="#%i">%s</a></li>\n' % (id, item.title)) # 写入1条新闻的列表项并指定id
file.write('</ul>') # 写入新闻列表的结束标签
id = 0 # 初始化HTML文件中的新闻id
for item in items: # 遍历新闻对象集合
id += 1 # 递增新闻id
file.write('<h2><a name="%i">%s</a></h2>\n' % (id, item.title)) # 写入1条新闻的标题并指定id
file.write('<p>' + item.body + '</p>\n') # 写入1条新闻的主体内容
file.write('</body>\n' # 写入HMTL文件主体的结束标签和HTML文件结束标签
'</html>')
在上方代码中,新闻id的作用是点击新闻标题列表中的某个标题时,能够让页面滚动到该新闻所在的位置。
这样的交互需要在标题的<a>标签中指定“href”属性为“#id”,“#”表示当前页面,“id”表示锚链接要连接到的目标,也就是<a>标签中“name”属性与“id”相同的页面内容。
(5)代理类
这个类,负责处理新闻源和输出目标,进行最终的分发。
具体实现过程,大家通过代码中的注释进行理解。
示例代码:
class NewsAgent: # 新闻代理类
def __init__(self):
self.sources = [] # 新闻源列表
self.destinations = [] # 输出目标列表
def add_source(self, source): # 添加新闻源的方法
self.sources.append(source)
def add_destinations(self, dest): # 添加输出目标的方法
self.destinations.append(dest)
def distribute(self): # 进行分发的方法
items = [] # 新闻对象列表
for source in self.sources: # 遍历每1个新闻源
items.extend(source.getItems()) # 从新闻源的生成器将所有新闻对象添加到新闻对象列表
for dest in self.destinations: # 遍历每1个输出目标
dest.receiveItems(items) # 调用处理新闻对象的方法处理新闻对象集合
(6)主程序
主程序负责指定新闻来源和输出目标,将来源和目标添加到代理类对象中进行处理,完成最终的分发。
具体实现过程,大家通过代码中的注释进行理解。
示例代码:
def runDefaultSetup(): # 主程序
agent = NewsAgent() # 创建代理类对象
server_name = 'web.aioe.org' # 指定NNTP服务器
group = 'comp.lang.python' # 指定访问的新闻组
window = 1 # 指定时间窗口
clpa = NNTPSource(server_name, group, window) # 创建新闻源对象
url = r'http://36kr.com/newsflashes' # 指定目标网页地址
titlePattern = r'"pin":"0","title":"(.{10,60})","catch_title"' # 组织提取新闻标题的正则表达式
bodyPattern = r'"description":"(.{100,400})","cover"' # 组织提取新闻主体内容的正则表达式
web = SimpleWebSource(url, titlePattern, bodyPattern) # 创建新闻源对象
agent.add_source(clpa) # 添加NNTP新闻源对象
agent.add_source(web) # 添加网页新闻源对象
agent.add_destinations(PlainDestination()) # 添加普通输出目标对象
agent.add_destinations(HTMLDestination('news.html', )) # 添加输出HTML文件目标对象
agent.distribute() # 调用分发方法
if __name__ == '__main__':
runDefaultSetup() # 执行主程序
以上就是这个练习项目的完整实现过程。
本节练习源代码:【点此下载】
转载请注明:魔力Python » 练习项目08:新闻采集(下)